“This is not possible with a digital video signal, since again, there is no way to tell which pixel is more likely than another to contain detail rather than noise.”
If you have enough samples, you can statistically work out which pixels contain noise and which contain information, that is the basis of image stacking. The signal to noise ratio is lowered by the root of the number of images.
Or do you mean images originally captured on a digital camera, not digital scans of film based capture?
I feel that scanning multiple prints at high resolution, and then stacking them achieves the same thing, but I’m probably missing something in my understanding here.
I’d love to see a proof of concept from your work, I’m happy to provide you with some higher resolution images, something like 6000x4000 pixels should be enough to work with?
I’m all for any technique that might improve the image.
I’m referring here to images captured digitally rather than on film. A digital image has a rectangular grid of pixels which are evenly spaced, each with luma/chroma information (in the best case scenario). Stacking a series of similar digital images will allow you to perform statistical analysis and improve the clarity of the image - for example two frames would agree on the color of a pixel and one frame would disagree, and the disagreeing pixel would be erased. However, what if that single pixel was the correct color? To return to the example above with the image of the blue edge: There is almost no chance of any single frame having a correct value for areas close to the edge, because of the blurriness of the dye clouds comprising the image. If there was an errant frame with the correct value, a statistical analysis would eliminate that value because it is not in agreement with the rest. In short, with a digital image, there is no way for an algorithm to reliably determine what is signal vs noise with only a single image, apart from applying a very destructive selective smoothing or sharpening operation.
Film is fundamentally different, in that you can determine the centers of dye clouds with far greater precision than the perceived resolution of the image. The halide crystals are microscopic, so determining where they were is determining precisely where the photons hit the film. There is no way to do this in a digital format. Since we can theoretically identify details with microscopic precision in film, image stacking using only the areas of actual detail will yield a far more impressive result than simply averaging the values of masses of overlapping dye clouds. Here’s how I envision it working:
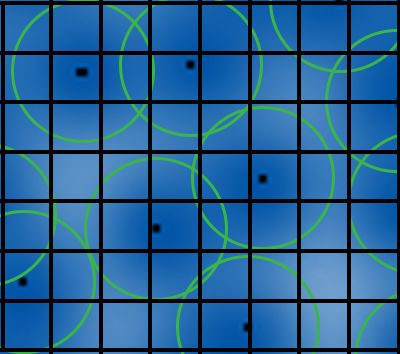
Say that this grid is the output resolution, which is less than the extremely high scanning resolution but still substantially above the resolution of the image. For each blue grain in the image, the center is found. This is where photons have hit the film, and is the only real image information. In this example, there are only about 6 dye cloud centers, meaning that only 6 pixels are assigned values. With enough sources, the entire pixel grid can be filled in. The way this differs from averages or even weighted averages is that only the real information in the image is in the final product. There is no blurriness resulting from interactions between the dye clouds, since the program intelligently uses dye cloud center proximity rather than averages.
And yes, I’d be happy to play around with some high-res images, though I’m no Dr Dre. If a proof of concept were to be made, it would need to be done by someone who knows how to code. I’m the 1% inspiration guy in this case. 😉